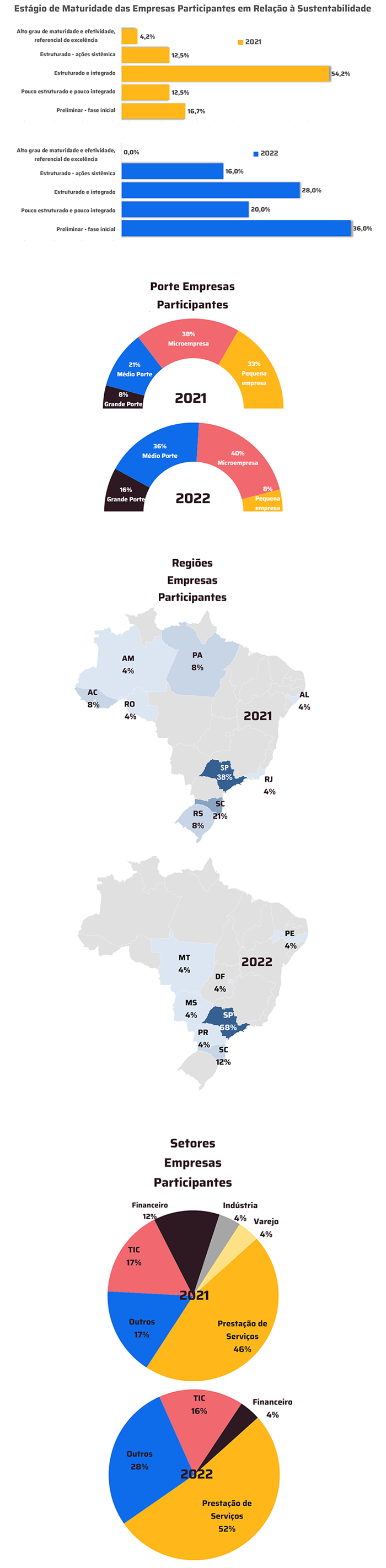
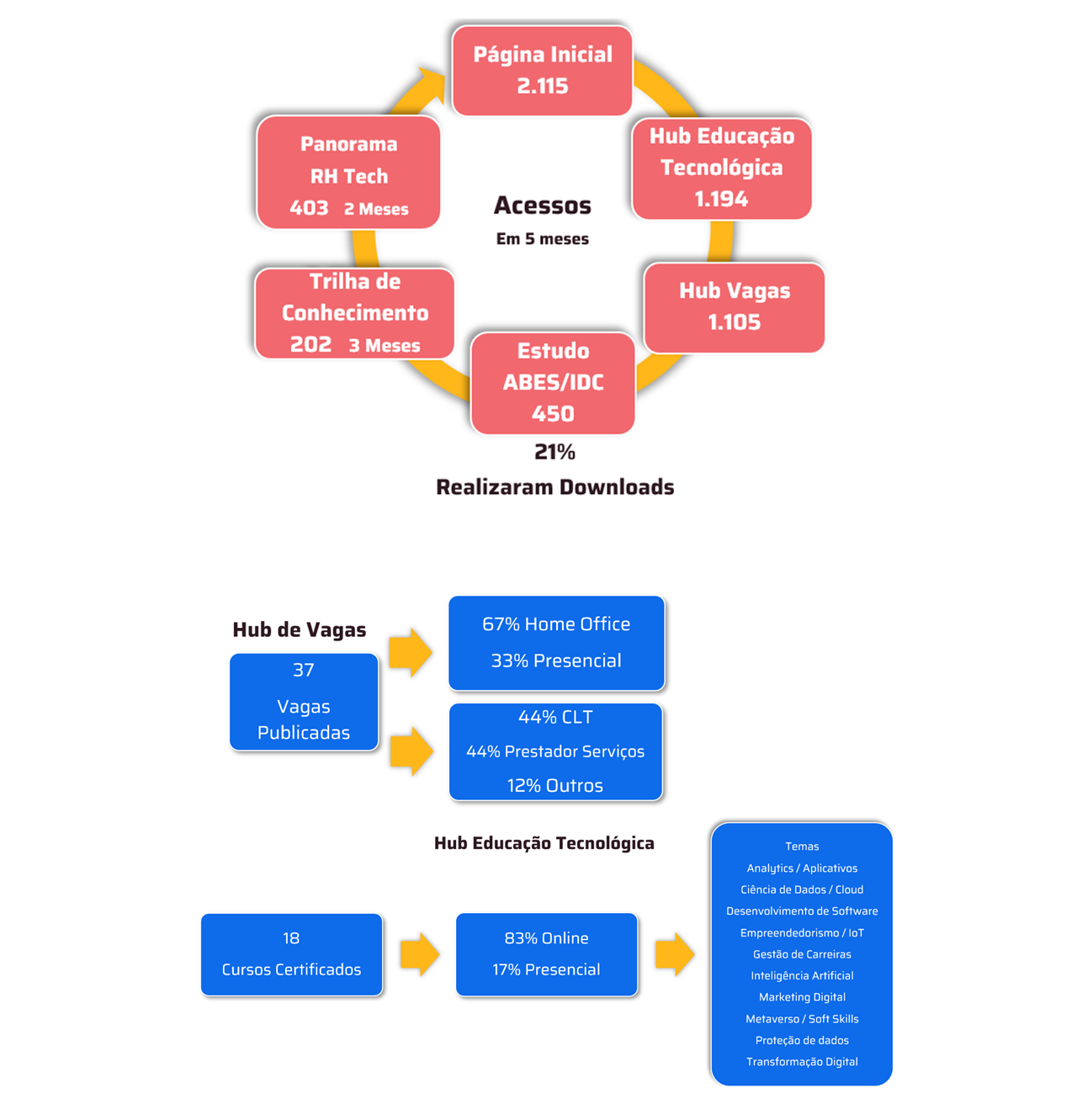
New developments seek to provide input for companies to adopt AI with confidence, improving business security and efficiency, with accelerated and correct data evaluation
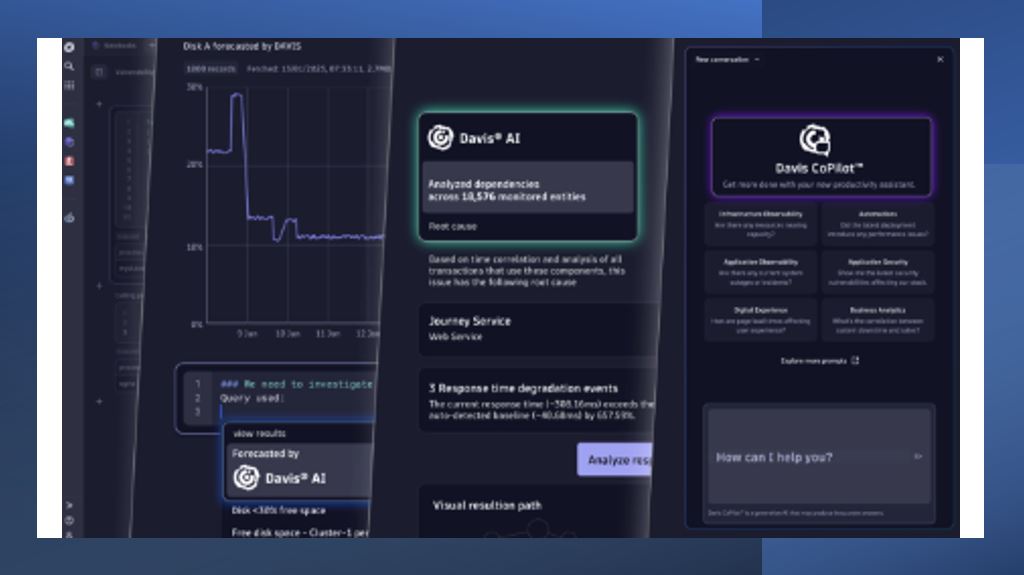
Dynatrace, a leader in unified observability and security, announces a series of innovations and expansions to its platform, including AI observability and data observability capabilities, as well as new automation options. Innovations are being announced globally this week, including the extension of its analytics and automation platform with Dynatrace AI Observability to provide comprehensive observability and security for large language models (LLMs) and Generative Artificial Intelligence-based applications. This improvement enables companies around the world to confidently and efficiently adopt Generative Artificial Intelligence as part of their focus on innovation, productivity and revenue.
The company also announces Dynatrace Data Observability, a new AI-based data observability feature. With Dynatrace Data Observability, teams can fully rely on all observability, security, and business event data on the Dynatrace platform to power the engine IA Davis, helping to eliminate false positives and provide reliable business analytics and consistent automations. Another novelty is the launch of OpenPipeline, a new core technology which offers customers a single pipeline to manage petabyte-scale data ingestion into the Dynatrace platform to drive secure and cost-effective analytics, AI, and automation.
“Dynatrace is at the forefront of using Artificial Intelligence in observability to enable companies across industries to use their data effectively to drive better business outcomes. Artificial Intelligence has been bringing countless benefits to companies, at the same time that it also presents many challenges. The new features we are bringing will transform the way companies see and use their information, and conduct their operations to achieve an even greater level of efficiency”, says Roberto de Carvalho, Regional Vice President for South America at Dynatrace.
Dynatrace’s main development and release highlights are:
1 – Dynatrace AI Observability – Dynatrace AI Observability is a comprehensive solution that enables enterprises to adopt AI with confidence, providing unparalleled insights across all layers of AI-based applications, helping to ensure security, reliability, performance and cost efficiency. The solution covers the entire Artificial Intelligence stack, including infrastructure such as Nvidia GPUs, foundation models such as GPT4, semantic caches and vector databases such as Weaviate, and orchestration frameworks such as LangChain.
It also supports leading platforms for building, training, and delivering Artificial Intelligence models, including Microsoft Azure OpenAI Service, Amazon SageMaker, and Google AI Platform. Dynatrace AI Observability uses IA Davis of the Dynatrace platform and other core technologies to offer a valuable and complete perspective on Artificial Intelligence-based applications. As a result, companies can deliver great user experiences while automatically identifying performance bottlenecks and root causes. Dynatrace AI Observability with Davis AI also helps companies comply with privacy and security regulations and governance standards by accurately tracking the source of output created by their applications. Additionally, it helps predict and control costs by monitoring the consumption of tokens, which are the basic units that Generative Artificial Intelligence models use to process queries.
Companies need AI observability that covers all aspects of their Generative AI solutions to overcome technology adoption challenges such as security, transparency, reliability, experience and cost management. Dynatrace is expanding its leadership in observability and AI to meet this need, helping customers embrace AI with confidence and security.
2 – Dynatrace Data Observability: Dynatrace Data Observability enables business analytics, data science, DevOps, SRE, security, and other teams to ensure that all data on the Dynatrace platform is of high quality. This complements the existing data cleansing and enrichment capabilities provided by Dynatrace OneAgent to ensure high quality of data collected by other external sources, including open source standards such as OpenTelemetry and custom instrumentation such as Dynatrace logs and APIs.
By adopting data observability techniques, companies can improve data availability, reliability, and quality throughout the data lifecycle, from ingestion to analysis and automation. Dynatrace Data Observability works with others core technologies of the Dynatrace platform, including Davis hypermodal AI, which combines predictive, causal, and generative AI capabilities to provide the following benefits to teams, helping to reduce or eliminate the need for additional data cleansing tools:
- Update: It helps ensure that data used for analytics and automation is up-to-date and available in a timely manner, alerting you to any issues.
- Volume: Monitors for unexpected increases, decreases, or gaps in data that may indicate undetected problems.
- Distribution: Monitors patterns, deviations, or outliers from the expected way data values are distributed in a data set, which may indicate problems in collecting or processing information.
- Scheme: Tracks the data structure and issues alerts on abnormal changes, such as added or deleted fields, to avoid unexpected results such as erroneous reports and dashboards.
- Lineage: Provides accurate root-cause details about where data is coming from and which services will be impacted, helping teams proactively identify and resolve data issues before they impact users or customers.
- Availability: Lever the infrastructure observability capabilities of the Dynatrace platform to monitor the use of digital services across servers, networks and storage, alerting on anomalies like downtime and latency, ensuring a constant flow of data from these sources for healthy analytics and automation.
3 – OpenPipelineThe: Enables full control of data upon ingestion and evaluates data streams five to ten times faster than legacy technologies, helping to boost security, facilitate management and maximize the value of data. Dynatrace OpenPipeline provides business, development, security, and operations teams with full visibility and control of the data being injected into the Dynatrace platform, preserving the context of the data and the cloud ecosystems from which it originates.
Because it evaluates flows faster than legacy technologies, it helps companies better manage the growing volume and variety of data coming from their hybrid and multicloud environments, empowering more teams to access the Dynatrace platform's AI-powered responses and automations without the need for additional tools.
OpenPipeline works with other core Dynatrace platform technologies, including Grail™ Data Lakehouse, Smartscape Topology and Davis Hypermodal AI, offering the following benefits:
- Petabyte-scale data analysis: Utilizes patent-pending stream processing algorithms to achieve significant increases in petabyte-scale data throughput.
- Unified data ingestion: Enables teams to ingest and route observability, security, and business data events – including dedicated Quality of Service (QoS) for business events – from any source and in any format, such as Dynatrace OneAgent, Dynatrace APIs and OpenTelemetry, with customizable retention times for individual use cases.
- Real-time data analysis on ingestion: Enables teams to convert unstructured data into structured, usable formats at the time of ingestion – for example, transforming raw data into time series data or metrics data and creating business events from log lines.
- Full data context: Enriches and maintains the context of heterogeneous data points – including metrics, traces, logs, user behavior, business events, vulnerabilities, threats, lifecycle events, and many others – reflecting the diverse parts of the cloud ecosystem from which it is sourced. originated.
- Controls for data privacy and security: Provides users with control over what data they analyze, store, or exclude from analysis, and includes fully customizable privacy and security controls, such as automatic and role-based masking of personally identifiable information (PII), to meet users' specific needs and regulatory requirements. customers.
- Cost-effective data management: Helps teams avoid ingesting duplicate data and reduce storage needs by transforming data into usable formats and enabling teams to remove unnecessary fields without losing insights, context, or analysis flexibility.