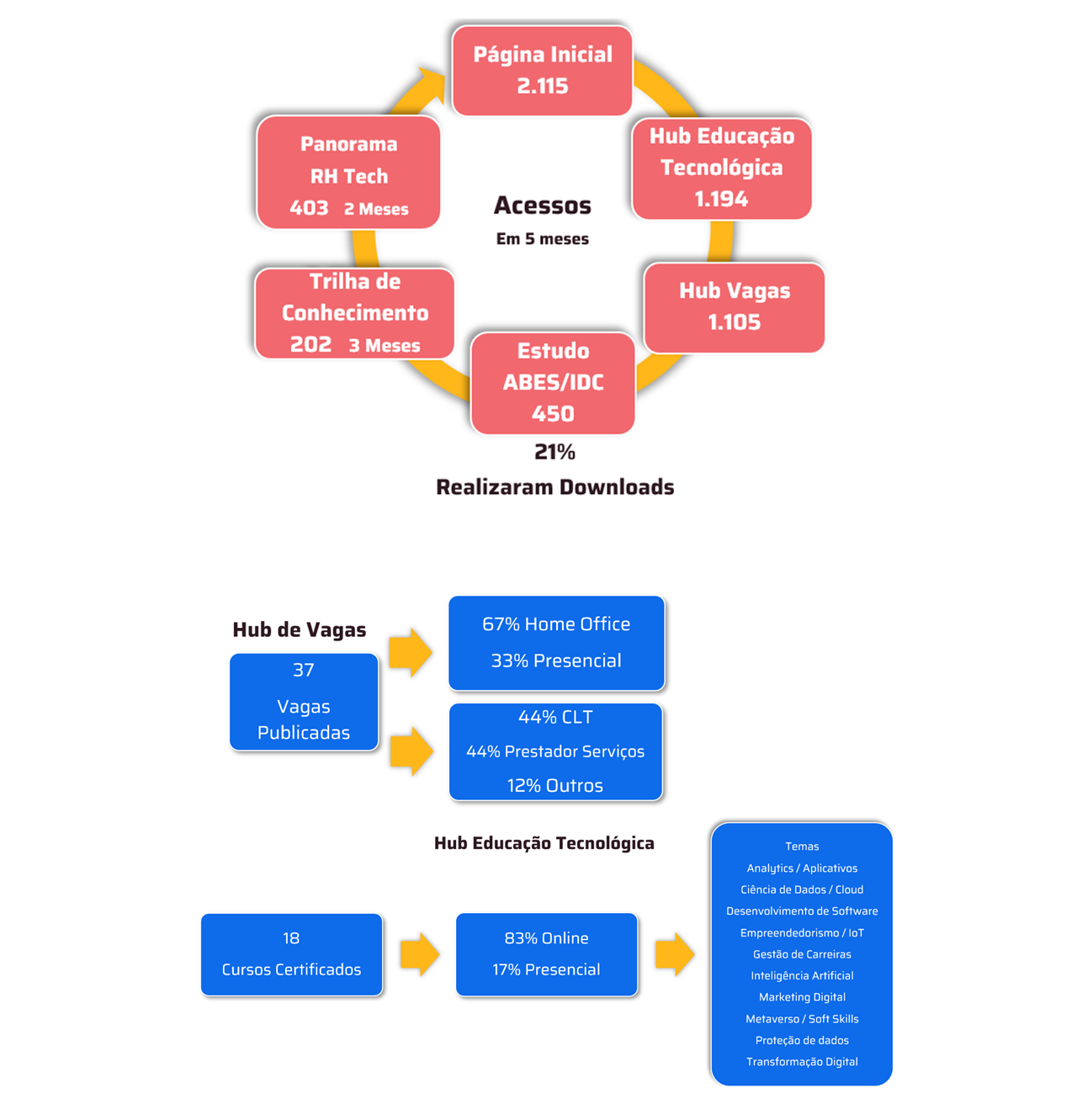
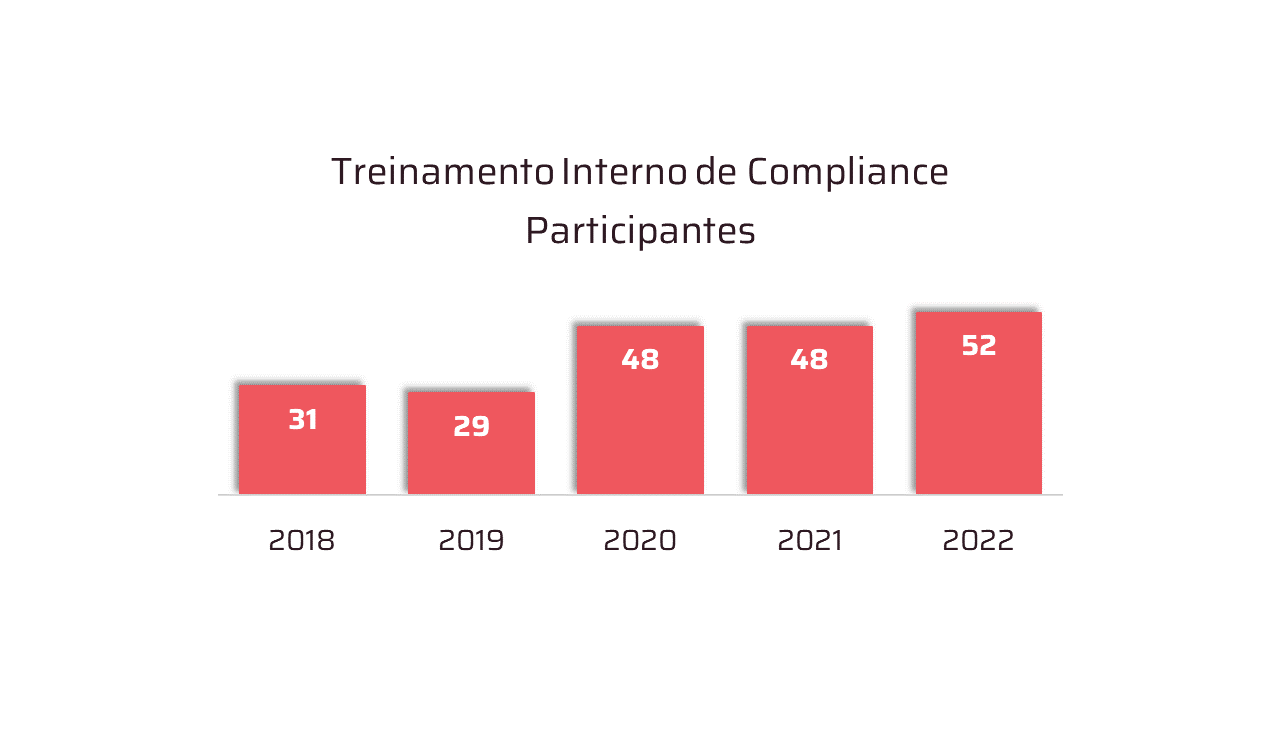
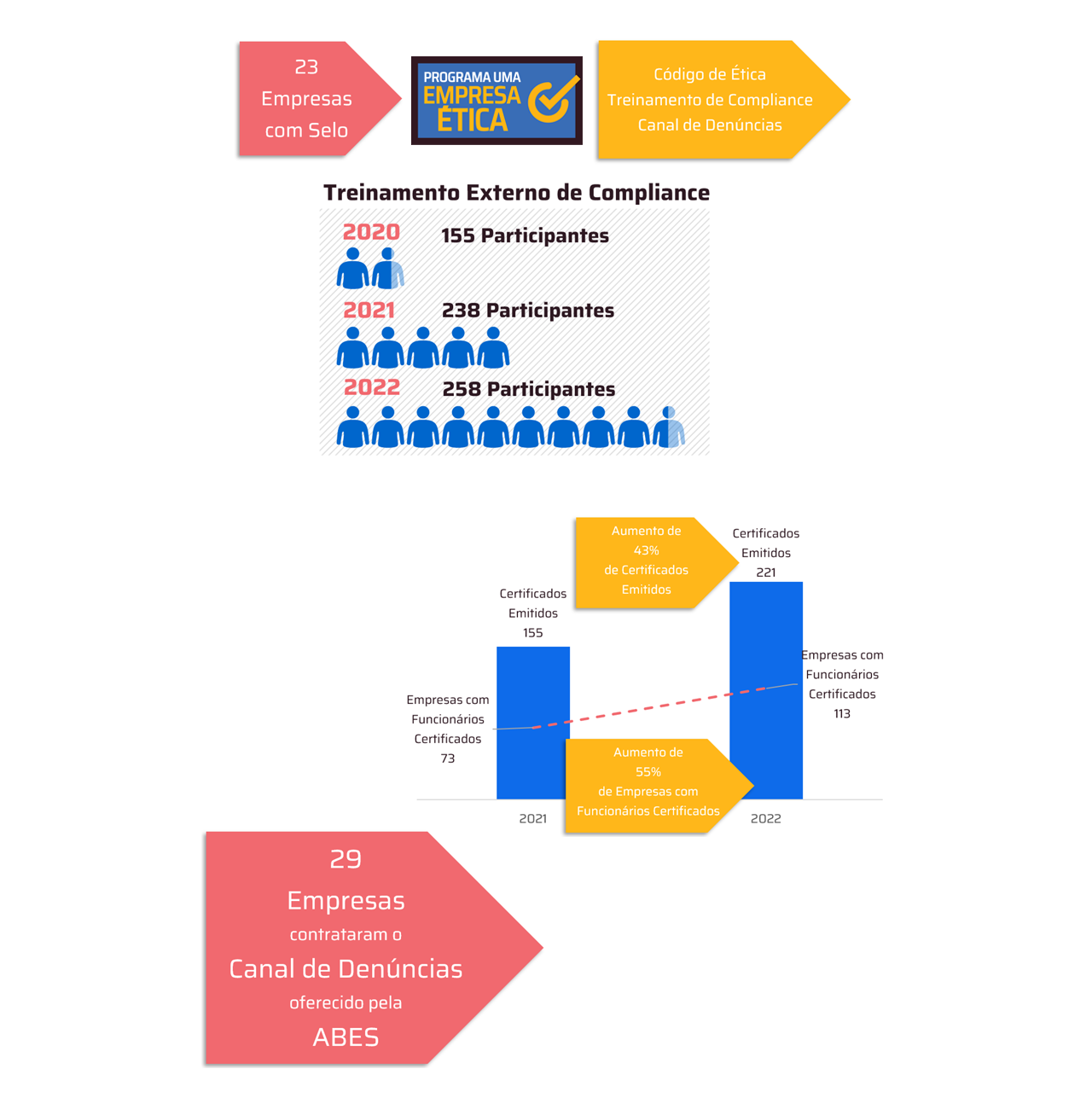
.jpg)
Por James Ruotolo, gerente sênior de soluções de prevenção à fraude do SAS
Um relatório recente desenvolvido pela Coalition Against Insurance Fraud(entidade norte-americana de combate à fraude) mostrou que as seguradoras estão cada vez mais em busca de análises preditivas e tecnologias de prevenção à fraude. A prova disso se dá no fato de que 95% dos entrevistados afirmam fazer uso de tecnologias antifraude, um aumento de 88% desde 2012. No entanto, representantes de seguradoras destacaram a ‘integração’ e a ‘má qualidade de dados’ como as maiores dificuldades na implementação de tecnologias de combate aos atos ilícitos.
Muitos dados, mas o que realmente analisar?
As seguradoras geram grandes volumes de dados diariamente. Entretanto, um dos maiores desafios que elas enfrentam na implementação de Analytics é o acesso às fontes corretas de informações. Os esforços são dificultados por múltiplas solicitações de ressarcimento, sistemas segregados pelas linhas de negócios, gestão de diferentes sistemas desenvolvidos internamente e sistemas de terceiros que armazenam dados críticos, como informações de faturamentos. Há ainda dados úteis não-estruturados, como notas de alegações. Além disso, existem novas fontes geradoras de informações, como as mídias sociais e dispositivos telemáticos.
A consolidação desses dados pode ser complexa, mas a utilização de ferramentas robustas de Data Quality e Data Integration podem ajudar, e muito, nesse processo. Ter a preocupação com a qualidade e integração de dados é fundamental para a produção de um modelo de sucesso.
Alguns sistemas de detecção de fraude não levam em conta a questão da qualidade dos dados. Dessa maneira, bons clientes podem ser incomodados com falsos positivos, oportunidades perdidas e alertas equivocados. A qualidade de soluções analíticas de fraude depende diretamente da qualidade dos dados de inseridos.
Quatro passos fundamentais para a preparação de dados para a análise de fraude:
1.Integração. Mesmo que os dados sejam gerados em diferentes lugares, como departamento de polícia, hospitais, instituições financeiras, empresas, etc, eles precisam ser integrados para a análise de possíveis fraudes. Durante essa etapa, é fundamental documentar os esforços de integração e garantir que eles se repitam e sejam auditáveis. Isto será essencial quando for colocada em produção a pontuação da análise de fraudes.
2. Falta de dados ou dados equivocados. Seu sistema contém indivíduos com números de CPF ou RG inválidos? Foi encontrado um arquivo de queixas sem número de telefone? Se estes erros são ignorados, eles podem ter um impacto negativo nos resultados de análises de fraude. Ferramentas como Data Quality podem ajudar a identificar, reparar e substituir dados que estão faltando ou que estão equivocados no sistema. Durante esta fase, também é útil padronizar formatos para campos comuns, como endereços.
3. Decifrar informações. Uma vez que os dados estejam agregados por mais sistemas, é importante identificar se os mesmos indivíduos, empresas e outras organizações existem em múltiplos lugares. Um sistema pode identificar nome e código de segurança, enquanto outro pode identificar nome e data de nascimento. Técnicas simples, presentes nas organizações, podem ser utilizadas para ligar esses dados e identificá-los como o mesmo indivíduo, mas os melhores resultados são encontrados quando tecnologias de Advanced Analytics são usadas para determinar a probabilidade de acerto.
4. Processar textos não estruturados. Mais de 80% dos dados de seguradoras são armazenados em formato de texto. Parte das melhores informações sobre arquivos de alegações é capturada na descrição de perdas ou campos de notas sobre queixas. Mas lidar com dados não é tão simples. Abreviações, acrônimos, jargões da indústria e erros de ortografia são comuns e precisam ser identificados pelas soluções de texto que contenham um vocabulário especialmente designado para dados de seguradoras. Durante a análise de texto, modelos adicionais de variáveis podem ser criados. Esta é uma forma poderosa de expandir o alcance de análises de fraudes, sem precisar incluir fontes externas de dados. Técnicas de Machine Learning e Natural-Language Processing devem ser usadas para encontrar e criar variáveis úteis para modelos de análise de fraude.
O gerenciamento eficaz de dados é essencial para qualquer implementação de Fraud Analytics. O investimento feito no processo de limpeza de dados resultará em melhores taxas de detecção de fraudes.